Understanding Data Lake Architecture
7/13/20247 min read
Data Lake Definition
A data lake is a centralized repository that ingests and stores large volumes of data in its original form. The data can then be processed and used as a basis for a variety of analytic needs. Due to its open, scalable architecture, a data lake can accommodate all types of data from any source, from structured (database tables, Excel sheets) to semi-structured (XML files, webpages) to unstructured (images, audio files, tweets), all without sacrificing fidelity. The data files are typically stored in staged zones—raw, cleansed, and curated—so that different types of users may use the data in its various forms to meet their needs. Data lakes provide core data consistency across various applications, powering big data analytics, machine learning, predictive analytics, and other forms of intelligent action.
The data lake concept revolves around creating a centralized repository for vast and diverse data from enterprise and public sources. Unlike traditional data storage methods like relational databases or data warehouses, which often have scale limitations and rigid structures, a data lake is designed to handle large volumes of structured and unstructured data more flexibly and cost-effectively.
Key Characteristics of a Data Lake
A data lake is distinguished by several key characteristics that facilitate its role in modern data management.
Centralized Repository:
It serves as a single source for storing all potentially relevant data from various sources, making it accessible for analysis across different departments and user groups within an organization
Flexibility and Agility
Data lakes allow for the storage of raw, unprocessed data alongside processed data, enabling users such as data scientists, business analysts, and developers to explore and analyze data in different ways without predefined schemas or transformations
Support for Advanced Analytics:
Users can apply a variety of analytics techniques, such as machine learning, graph analytics, ad hoc querying, and business intelligence dashboards, to derive insights and make data-driven decisions.
Compute cost:
By leveraging scalable, distributed storage and processing technologies (like Hadoop and Spark) on generic hardware and often utilizing cloud services, data lakes aim to provide better economies of scale compared to traditional data storage solutions.
Promotion of Creativity and Innovation:
Data lakes encourage a more exploratory approach to data analysis, allowing users to discover new insights and formulate new questions based on the data available. This contrasts with traditional methods where data access and analysis are more rigidly
Data Lake Foundation
A data lake can be broadly categorized across four distinct buckets:
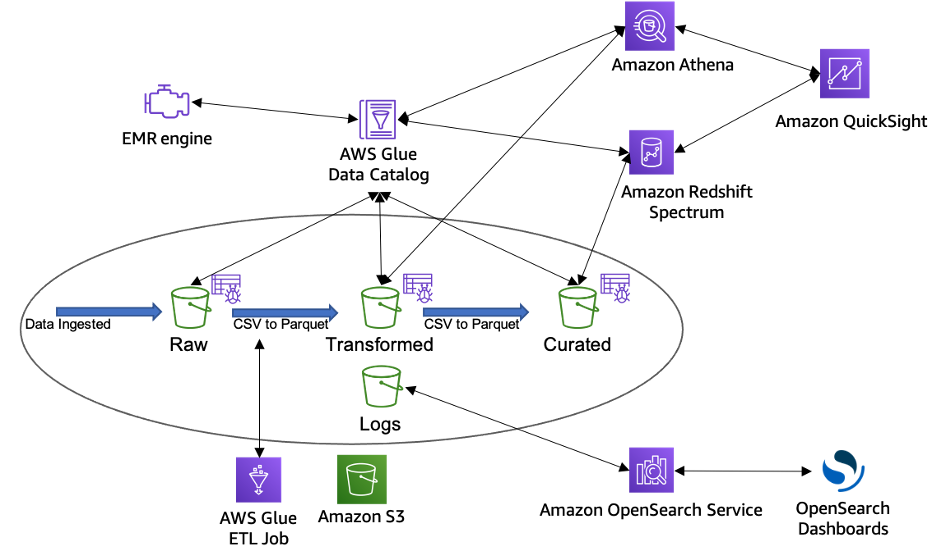
Raw data
Data is ingested from the data sources in the raw data format, which is the immutable copy of the data. This can include structured, semi-structured, and unstructured data objects such as databases, backups, archives, JSON, CSV, XML, text files, or images.
Transformed
This bucket consists of transformed data normalized to a specific use case for performance improvement and cost reduction. In this stage, data can be transformed into columnar data formats, such as Apache Parquet and Apache ORC, which can be used by Amazon Athena.
Curated
The transformed data can be further enriched by blending it with other data sets to provide additional insights. This layer typically contains S3 objects which are optimized for analytics, reporting using Amazon Athena, Amazon Redshift Spectrum, and loading into massively parallel processing data warehouses such as Amazon Redshift.
Logs
This bucket stores process logs for data lake architecture. The logs can include S3 access logs, CloudWatch logs, or CloudTrail logs
What to Consider When Designing a Data Lake
As part of designing a data lake, it is important to identify services to make the desired architecture approach possible and practical for the enterprise, business users, and data scientists alike. When designing a data lake it is important to consider the following;
Storage
Data lake storage requires scalability for vast amounts of structured and unstructured data. Cloud-based object storage, such as AWS's Amazon S3 and Glacier, offers reliable redundancy and cost-effective archiving options. These solutions support various data types with minimal administrative overhead and enhance reliability, security, and analytics capabilities for the entire data management framework, crucial for supporting analytics clusters and data processing engines.
Compute - Different analytics workloads have varying compute resource needs. For instance, streaming analytics require high throughput, batch processing can be CPU-intensive, Apache Spark benefits from ample memory, and AI tasks often leverage GPUs. AWS provides extensive flexibility compared to other providers and on-premises setups like Hadoop, which link storage and compute per node. AWS offers compute-optimized, memory-optimized, and storage-optimized instance types, avoiding the drawbacks of a "one-size-fits-all" approach. Decoupling compute from storage allows efficient utilization of specialized resources.
Analytics - A data lake facilitates versatile data analysis across various use cases. AWS supports diverse analytics approaches with services like Amazon Redshift for data warehousing, Amazon Athena for SQL queries on demand, Amazon EMR for running frameworks like Hadoop, Spark, Presto, Flink, and HBase, Amazon QuickSight for business intelligence, and Amazon Elasticsearch Service for logs and text analysis. This eliminates the need for data migration across different environments, reducing overhead, costs, and delays.
Databases - While data lakes primarily handle unstructured data, structured data often benefits from organized processing. AWS offers Amazon Relational Database Service (RDS) for popular commercial and open-source databases, including Amazon Aurora for MySQL. Additional services like Amazon DynamoDB cater to NoSQL models such as key-value and document stores, while Amazon ElastiCache enhances performance with Redis and Memcached, ensuring flexibility for various data lake applications.
Real-time Streaming Processing: - Beyond storage and batch processing, AWS addresses real-time data needs with Amazon Kinesis. This platform supports the collection, storage, processing, and analysis of streaming data, facilitating the development of custom streaming data applications to meet specialized requirements.
Artificial Intelligence: AWS supports artificial intelligence and machine learning applications with accessible services like Amazon Machine Learning, which simplifies algorithm use with wizards, APIs, and guidance. Additional AI services include Amazon Polly for text-to-speech, Amazon Lex for natural language processing and chatbots, and Amazon Rekognition for image analysis and classification, enabling the integration of smart functionalities into applications.
Security Services: Security, privacy, and governance are critical for trusting sensitive data in a cloud data lake. AWS offers comprehensive security services including IAM for roles management, CloudWatch for event monitoring and response, CloudTrail for audits and logging, KMS for encryption key management, a security token service, and Amazon Cognito for user account management and authentication. AWS environments adhere to stringent certifications like ISO 27001, FedRAMP, DoD SRG, and PCI DSS, with assurance programs supporting compliance across 20+ standards such as HIPAA and FISMA.
Data Management Services: Data management involves ensuring proper ETL processes across different platforms. AWS introduces AWS Glue as an ETL engine, facilitating understanding of data sources, data preparation, and reliable loading into data stores.
Application Services: Integrating higher-level applications enhances the functionality of a data lake. AWS provides robust utilities for IoT and mobile applications, complementing the data lake's capabilities effectively.
Challenges and Solutions in Implementing a Data Lake
Implementing a data lake can present a myriad of challenges, each of which must be thoughtfully addressed to ensure a seamless integration. One of the foremost challenges is data ingestion complexities. Organizations often struggle with the volume, variety, and velocity of incoming data streams. To mitigate this, it is essential to employ scalable data ingestion frameworks that can handle large datasets efficiently. Technologies such as Apache Kafka and AWS Kinesis can facilitate real-time data streaming and batch processing, providing a robust foundation for data ingestion.
Managing data quality and consistency is another critical challenge. Data lakes can become data swamps if not managed properly, leading to unreliable and unusable data. Implementing data validation, cleansing, and transformation processes is vital. Automated tools and frameworks such as Apache NiFi can ensure that data is consistently formatted and free of errors. Regular audits and data profiling can further enhance data quality, ensuring that the data lake remains a valuable resource.
Effective data governance is paramount in maintaining the integrity and usability of a data lake. This involves establishing policies and procedures for data access, usage, and lifecycle management. Implementing role-based access controls (RBAC) and encryption can safeguard sensitive information, while metadata management tools can provide a comprehensive view of data lineage and provenance. Additionally, adopting a data governance framework like DAMA-DMBOK can help standardize practices and ensure compliance with regulatory requirements.
Integrating diverse data sources poses another significant challenge. Data lakes must be capable of ingesting data from myriad sources, including relational databases, NoSQL databases, and external APIs. Utilizing data integration platforms such as Talend or Informatica can streamline this process by providing connectors and workflows that facilitate seamless integration. Ensuring compatibility and interoperability between different data formats and systems is crucial for a cohesive data lake ecosystem.
Data security and privacy are critical concerns in any data lake implementation. With the increasing prevalence of data breaches, it is imperative to implement robust security measures. Encryption at rest and in transit, along with stringent access controls, can protect data from unauthorized access. Additionally, compliance with data protection regulations such as GDPR and CCPA is essential. Regular security audits and vulnerability assessments can help identify and mitigate potential risks.
Case studies provide valuable insights into overcoming these challenges. For instance, Netflix successfully implemented a data lake that ingests and processes petabytes of data daily. By leveraging technologies like Apache Kafka and Apache Spark, Netflix ensures real-time data processing and analytics. Similarly, Capital One's data lake initiative focuses on data governance and quality, employing automated tools for data cleansing and validation. These examples illustrate that with the right strategies and technologies, the challenges of implementing a data lake can be effectively addressed.
Future Trends and Innovations in Data Lakes
As organizations continue to harness the potential of big data, the landscape of data lakes is evolving rapidly. One of the most notable advancements is the integration of artificial intelligence (AI) and machine learning (ML) within data lake environments. These technologies facilitate enhanced data analytics by automating complex processes, enabling predictive analytics, and uncovering hidden patterns within massive datasets. The synergy of AI and ML with data lakes is poised to transform how businesses derive insights and make data-driven decisions.
Another significant trend in data lake technology is the emphasis on real-time data processing and streaming analytics. As the demand for immediate insights grows, data lakes are increasingly incorporating capabilities to handle real-time data ingestion and processing. This shift enables organizations to react promptly to emerging trends, anomalies, and business opportunities, thereby enhancing operational agility and competitiveness.
The evolution of data privacy regulations is also shaping the future of data lakes. With the implementation of stringent data protection laws, such as GDPR and CCPA, organizations must ensure compliance while managing vast amounts of data. Innovative data lake solutions are emerging to address these challenges by offering robust security features, data governance frameworks, and privacy-preserving techniques. These advancements help organizations maintain regulatory compliance while leveraging the full potential of their data assets.
Additionally, the rise of hybrid and multi-cloud environments is influencing the development of data lakes. Organizations are increasingly adopting these environments to achieve greater flexibility, scalability, and cost-efficiency. Modern data lake solutions are being designed to seamlessly integrate with various cloud platforms, providing unified data management across diverse infrastructure landscapes. This integration supports the growing trend toward hybrid and multi-cloud strategies, enabling organizations to optimize their data storage and processing capabilities.
Looking ahead, expert insights suggest that data lakes will continue to evolve, driven by advancements in technology and changing business needs. The adoption of AI and ML, the emphasis on real-time processing, compliance with data privacy regulations, and the support for hybrid and multi-cloud environments are set to define the future of data lakes. These innovations will empower organizations to unlock new levels of data-driven insights and drive strategic growth in an increasingly data-centric world