Data Lakehouse: Bridging the Gap Between Data Lake and Data Warehouse
The tech industry has struggled with efficient big data storage and analysis, leading to dissatisfaction and high costs from hybrid data lake-warehouse approaches. Data warehouses handle structured data for BI, while data lakes manage unstructured data for ML, causing complex ETL processes and governance issues. Bill Inmon and Mary Levins introduced the data Lakehouse to integrate these benefits, providing cost-effective storage and compatibility with engines like Spark, aiming to streamline data operations and improve efficiency.
Augustine
7/1/20242 min read
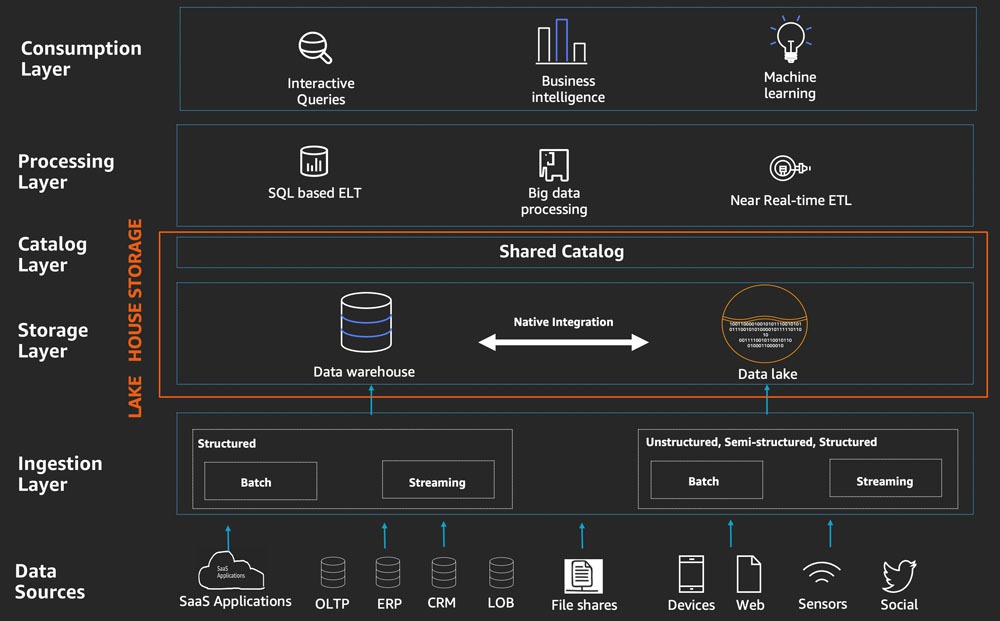
What is a Data Lakehouse
Bill Inmon and Mary Levins first promulgated the idea of data Lakehouse in 2021. They seek to address the pertinent storage and high cost of traditional Architectures such as data lakes and data warehouses which pose a significant challenge in data storage and costs.
A data lakehouse is a modern data architecture that integrates the flexibility and scalability of data lakes with the reliability and performance of data warehouses. It allows for the storage of all types of data, including structured, semi-structured, and unstructured data, in a unified platform. By leveraging the strengths of both data lakes and data warehouses, data lakehouses enable organizations to perform advanced analytics and business intelligence more efficiently.
Key Differences Between Data Lake, Data Lakehouse, and Data Warehouse
To better understand the unique advantages of a data lakehouse, it is essential to compare it with traditional data lakes and data warehouses. The table below highlights the key differences among these data storage solutions:
Data warehouses, data lakes, and data lakehouses serve distinct purposes and offer different advantages depending on the data users' needs and the data's characteristics.
Data Warehouses:
Store structured data for analytics, typically used by business intelligence teams for reporting and analysis.
Structured, and organized data with well-defined schemas for efficient querying and reporting.
Best for business environments requiring clean, structured data for routine analysis.
Data Lakes:
Store raw, unfiltered data (structured, semi-structured, or unstructured) for advanced analytics and exploration.
Flexibility to handle diverse data types and support complex, ad-hoc analyses, machine learning, and AI applications.
Ideal for data scientists and analysts who need to work with raw data to derive insights and conduct exploratory analysis.
Data Lakehouses:
Combine the strengths of both data warehouses and data lakes, providing structured data capabilities alongside the flexibility to handle raw data.
Offers both structured data management for efficiency and raw data flexibility for advanced analytics, bridging the gap between traditional data warehousing and data lake capabilities.
Suitable for organizations needing a hybrid approach that supports a range of data use cases without the need for separate infrastructures.
Benefits of Adopting a Data Lakehouse
Organizations that adopt a data lakehouse architecture can enjoy several benefits, including:
1. Unified Data Management: A data lakehouse allows for the seamless integration of various data types in a single platform, simplifying data management and reducing complexity.
2. Cost Efficiency: By combining the low-cost storage of data lakes with the high-performance capabilities of data warehouses, data lakehouses provide a cost-effective solution for managing large volumes of data.
3. Enhanced Analytics: Data lakehouses support advanced analytics and machine learning, enabling organizations to extract valuable insights and make data-driven decisions more effectively.
4. Improved Data Governance: With comprehensive data governance features, data lakehouses ensure data quality, security, and compliance, mitigating risks associated with data management.